“创造市场”与“算法进化”,中美AI竞速的岔路口

中美多维差异背后,技术落地路径已然不同。
“人工智能的商业模式,是要创造一个市场,而非一个算法”。这是世界AI泰斗Michael I.Jordan的观点。
而当前的全球AI市场,占据主导地位的中美双方,却也走出了两条截然不同的技术路径,前者执着于前沿技术的探索,后者则发力应用优化和商业化落地。
南辕北辙的两个方向,或许已经无法直接进行排位先后、优劣的对比,但对于应用和落地,中国明显有自己的鲜明主张,甚至即将完成超越。谷歌中国区前负责人李开复表示,预计到明年年初,中国的应用普及速度将远远超过美国。
只是,这一路走来,中国企业付出了多少,鲜为人知。
国内AI大模型:从“雨后春笋”到“销声匿迹”
2022年11月,自ChatGPT推出后,国内市场被激发出前所未有的热情。随后在2023年初,国内涌现出首批大模型创业者,掀起了一阵大模型创业的小高潮。同年6月,百模大战正式打响。
耗时不到三个月,中国就诞生了超200款大模型,但到23年12月,持续更新的模型便迅速减少至156款。再到今年5月,便仅剩19款。很多大模型如同昙花一现,稍纵即逝。
而被业界称为"六小虎"的智谱AI、零一万物、百川智能、MiniMax、月之暗面和阶跃星辰,也开始进行业务调整,有的暂停了预训练模型的研发,有的则逐渐退出C端市场,转而聚焦B端业务,甚至还有公司进行了人员缩减。
这一现象背后,可以预见的是单靠融资驱动的商业模式已经成为过去式。面对全球AI大模型百舸争流的形势,中国AI产业需要深刻反思并寻求破局之机。而首要目标就是回归商业本质,摒弃单纯追求技术参数竞赛的浮躁心态,更加注重市场需求导向的研发与应用创新。
彼时,国内AI大模型开始进一步分化。按模态划分,大模型可分为自然语言处理(NLP)大模型,视觉(CV)大模型、多模态大模型等;按照部署方式划分则可以分为云侧大模型和端侧大模型两类。
其中,云侧大模型又有通用大模型和行业大模型两种,通用大模型具有适用性广泛的特征,目前更具代表性的有文心一言、通义千问、讯飞火星等,行业大模型则具有专业性强的特点,针对特定行业(如金融、医疗、政务等)的需求进行模型训练。
可见,国内AI大模型的应用路线开始日渐清晰,大致途径为“基础大模型→行业大模型→终端应用”。
值得注意的是,继百模大战降温、应用路线清晰后,价格战也开始了。一个典型例子就是,今年5月21日,百度宣布两款大模型免费开放:Speed和Lite,这两个相对轻量的大模型免费提供,而最强大的大模型依然收费。
尽管,低价甚至免费可以增加用户基数,但也给企业带来了不小的生存压力,毕竟这违背了最基本的商业逻辑。但如果技术和产品的竞争力足够强,那么也无需主动去参与价格战。
如此一来,价格战的开启虽然不是一个好兆头,但也从侧面推动AI技术创新进入了新的加速期。
中美多维差异背后,技术落地路径已然不同中美多维差异背后,技术落地路径已然不同
在全球人工智能持续竞速的背景下,中美双方孰强孰弱一直是备受关注的议题。据悉,目前全球发布的大模型总数中,中美合计占约80%,处于绝对的主导地位。
具体来看,中美双方之间在技术背景、文化属性、市场环境、人才培养、算力、数据等维度上都存在差异。
技术背景方面,美国的科技发展尤其注重“技术优先”和“知识密度优先”,行业、企业之间重视基础创新,对于新兴的事物保持着较强的鼓励和促进态度。同时,整个生态上的分工也更为明确,形成了一套较为完整且兼具创新的生态链,从而共同推近统一目标。
国内相较更为多样化,并尝试依托于更多的应用爆发以及市场的多样性来加速发展。同时在发展过程中,对于安全、可控,以及持续性和自主性等维度的要求会更高。
又因为技术背景和市场环境的缘故,双方在商业模式上的区别也较为明显。美国AI公司更多用的是软件模式,可以快速起量;国内公司则更擅长性能调优,多采用个性化定制的服务方式。
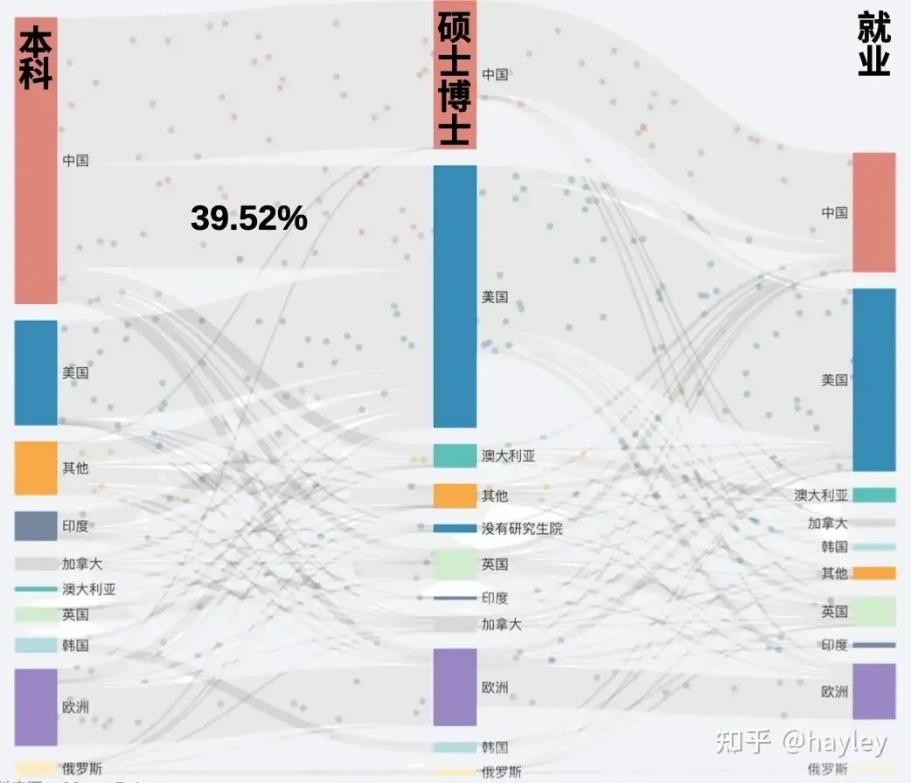
图源来自知乎@hayley
人才培养方面,从上图可以看出,国内在人工智能人才培养上的比例分布情况。国内人工智能人才的本科比例较高,但硕士和博士比例逐渐下降。
原因在于大量人才选择出国深造和工作。相关数据显示,美国39.52%的人工智能人才实际上来自于中国。这使得错失更多高端人才的中国,在基础研发上阻力相对较大。
算力方面,由于国内在先进制程芯片以及计算密度上不占优势,所以仍处在落后于美国的阶段。但基于国内政策及资本的积极态度,长远来讲,算力难题是有解的。
而算力之外,数据是另一个限制中国AI产业发展的重要因素。一方面是因为大量数据的私有化,导致获取数据的成本高,另一方面,因为处理数据的成本居高不下,所以企业之间对自己的数据策略(包括数据配比,数据来源,数据加工等等)高度保密。
最后也最关键的是,产业发展路径方面,美国倾向于从底层开始限制开源生态的分发过程,并试图通过限制开源来抑制产业创新。而国内则倾向于大力推动开源模型的发展,从而更加贴合垂直行业的应用落地。
就影响而言,美国所主张的限制开源,对国内不会造成太大影响。尽管底层研发技术仍有差距,但GPT-3.5的出现意味着技术取得了阶段性的突破,而且因为开放使用,国内已经获取了开源模型。因此,技术革命的传播速度快于立法监管的速度,导致监管是失效的。
综合来看,多个角度上的差异造成了中美双方在技术落地路径上的大相径庭,美国仍旧处于从0-1技术探索的前沿阵地,而国内则更关注商业落地并贴合市场需求进行应用优化。
想“超车”美国,还得看“应用线”
在国内企业转向美国的开源人工智能模式以求迎头赶上的同时,美方也陷入一个相对尴尬的境地。因为,他们一直试图通过限制微芯片销售和遏制投资来减缓国内的进步,但却无法阻止企业为了促进软件的普及而选择公开发布的做法。
美国在开源模型上的“两头为难”恰好为国内企业实现“超车”提供了机会。
从Sora和GPT-4这两大爆款来看,Sora在算法上的突破并不大,效果展示上的惊艳更多源于巨亮算力的堆集,它解决了决帧与帧之间的时序一致性问题,但同时导致Sora的视频生成成本短时间内无法降低。
而GPT-4虽然强大,其成本高企同样是当下最难跨越的现实问题之一。这也使得企业在实际应用中往往选择性价比更高的解决方案,如开源模型或规模更小的商用模型。
而且,一旦最好的开源技术来自于中国,美国开发者最终将由主动转为被动,甚至需要在中国技术的基础上构建自己的底层系统。
可见,追求技术领先的美国,在跨出商业化落地的“临门一脚”时已经被成本“绊倒”,未来还有可能因此陷入僵局。
形成鲜明对比的是,中国的科技投资者在推动人工智能时追求尽快转亏为盈,这意味着资金正在流向易于执行的应用,而不是更具抱负、专注于基础研究的目标,杜克大学约翰·科克电气与计算机工程杰出教授陈怡然这样说到。
与此同时,中国对人工智能的投资中,多达50%投向了监控所需的计算机视觉技术,而不是为生成式人工智能建立基础模型。
尤其对于国内本地市场的需求,百度文心一言、阿里通义千问等国内自主研发的大规模模型,在应对广泛且普遍的应用场景时,已经充分展现了其实用性与高效性。诚然,在应对极其复杂或特定复杂需求时,这些模型与全球顶尖的大模型相比,尚存在一定的性能差距。
然而,就当前多数生产工具的实际需求而言,无论是通过开源途径获取的模型,还是国内商业化提供的解决方案,均能提供基本且相对令人满意的服务支持。
尤为值得一提的是,随着各类应用场景的不断拓展与深化,国内大模型的实际应用落地进程正显著加速,展现出蓬勃的发展态势。
由此来看,中国虽然暂时无法通过现有的大模型实现技术上的全面超越,但美国也无法进行有效封锁,开源技术既是中国AI发展如此迅速的关键原因,也将是中国取得领先地位的机遇。
而技术路径上的差异已经让美国陷入阶段性停滞不前,国内应该继续专注于应用开发,从而缩小商业化价值上的差距。
长远来看,美国如果真限制开源,那么这将是技术衰落的开始,同时也是中国正式崛起的开始。
战局最终将如何演化,我们静待时间揭晓。
